
ChatGPTが連日ニュースで取り上げられるなど、「生成AI」は人々に広く知られるようになりました。大人から子どもまで、遊びで使ってみたという人はもはや珍しくありません。
しかし一方、その研究開発や動作の仕組みまで世に知れ渡っているのかといえば、そうではないでしょう。また社会的視点でも、「何が問題なのか分からない」「それのせいでどういうことが起こるっていうのか」など、首をかしげる人は多くみられます。
そこで今回は、生成AIとはそもそも何なのかから入り、問題点はどこにあるのか、なぜこんなに大きな問題になっているのかを解説しようと思います。
参考リンク:人工知能(AI)の問題点・デメリット5選と、人間の未来
目次
生成AIとは?
生成AI(またはジェネレーティブAI)とは、人が作りたいものを入力すると、それに応じたテキスト(文)、画像、音声などを自動で生成できるコンピュータープログラムのことをいいます。「人工知能(artificial intellegence、略してAI)」と呼ばれているプログラムの一種にあたります。
具体的に言うと、例えば、画像生成AIサービスで「教室で本を読んでいるかわいい女の子」と打ち込むと、それらしいイラストがたった数分で生成されてきます。実物を見れば「百聞は一見に如かず」ではないでしょうか。
そもそも人工知能とは?
では、そもそも人工知能とは何のことをいうのでしょうか? 話の全体像が見えるよう説明しておきましょう。
人工知能とは、一般に「人間のような知能があるように見えるプログラム」を指しています。具体的には、
- ネットショップのおすすめ商品の表示
- ゲームの敵キャラクターの動き
- パソコンやスマホの顔認証
などがそれに入ります。
なんだ、そんなのは新しくもめずらしくもないじゃないか、と思ったかもしれません。実は、人工知能と呼ばれ得るプログラムは、私たちの身の回りに以前からたくさんありました。例えば、デジタルカメラには自動で人の顔にフォーカスする機能がありますよね? あれもれっきとした人工知能。そう呼ばれることがなかっただけです。それが最近やたらと「AI搭載」などと言われるようになったのは、人工知能が近年「ブーム」のような状態になり、また加えて、コンピューター工学研究者の間でもその定義が一定せずあいまいなのに乗じて、各種メーカーがそう呼びたがるようになったから、という感じです。
文や画像、音声などを自動で作成する生成AIは、こうした様々な人工知能の一種という位置づけです。
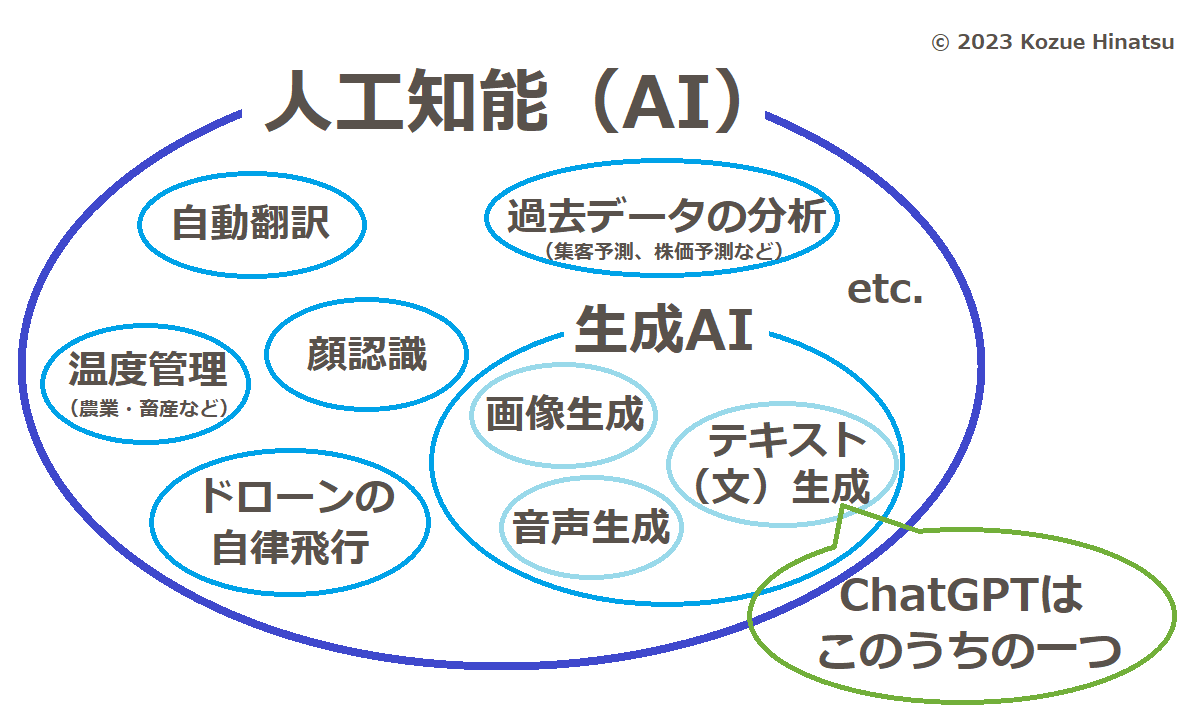
人工知能全般でいえば、軍事利用といった深刻な問題点や、他方で、私たちの身の回りで仕事の大幅な負担軽減につながるなど、じつに様々な話題や論点があります。その全般については別の記事で解説しましたので、以下リンクから参照ください。
関連記事:人工知能(AI)の問題点・デメリット5選と、人間の未来
「機械学習」―AIの独特な開発方法
生成AIの問題点を理解するためにいま最も頭に置くべき点は、人工知能は開発方法が独特だということです。「機械学習」といって、人工知能に大量のデータを取り込ませることで「学習」させていくのです。
機械学習には、人が正解・不正解を教える(いわゆる「教師あり学習」)、人工知能自身に情報同士の関連性を探させる(「教師なし学習」)、成功したらそれに応じた得点を与える(「強化学習」)といった方法があります。それらを使い分けたり組み合わせたりすることで、開発方法も改良されてきました。中でも、人間のように物の特徴をとらえることに秀でた「ディープラーニング」は革新的で、画像や音声の認識技術を飛躍的に向上させました。
具体的に言うと、例えば、ネコを判別できるプログラム(=人工知能)を作るとしたら、開発者はまず、途方もない数のネコの画像と、イヌやトラなど別の画像をそれにインプットします。そして実際に「ネコの判別」を実行させてみて、学校の先生のように「正解、これはネコ」「違う、これはイヌ」「正解、色は違うけどこれもネコ」と正解・不正解を教えます(教師あり学習)。これを繰り返すうちにだんだん精度が上がっていき、ついには人が見て「なるほど、このプログラムはネコを判別できている」とうなずけるレベルに到達するのです。そもそも人工知能は、人間の脳をコンピューターで模して再現したプログラムです。なので、開発方法でも人間が勉強するプロセスをなぞっているのです。
この「大量のデータを取り込ませる」という開発方法が生成AIの大きな問題につながっているので、最初にしっかり押さえておくとよいでしょう。
生成AIのいま
最新のテクノロジーのように取りざたされている人工知能。ですが、実はコンピューター工学の世界では、その研究開発は1950年代には本格的に始まっていました。なにもいま突然出てきた新技術というわけではないのです。初期の研究で作られたのは何の役にも立たない程度だったので、研究室の外に出て人目に触れることも、商品化されることもありませんでした。
滞っていた研究開発が近年一気にジャンプアップしたきっかけは、インターネットの登場です。世界中の無数の人が、ネットに文や画像をアップし、誰でも見られるよう公開するようになったのです。人工知能の研究者にとって、これは願ってもないことでした。インターネット以前には存在しなかった、機械学習に必要な「大量のデータ」が出現したのです。こうしたインターネットの登場にコンピューターの性能向上が相まって、長年行われてきたAIの研究開発が飛躍的に進み、とうとう社会に出てくる段階まできた――それが私たちがいま目にしている状況ということになります。
生成系でまず世に出てきたのは、画像の生成でした。2022年に「Stable Diffusion」「NovelAI Diffusion」などが次々リリースされると、遊び感覚でイラストを出力させてみる人が世界中に出て、大きな話題になりました。
続いて登場したのがテキスト(文)の生成AIで、話題沸騰のChatGPTはこの種類にあたります。
テキスト生成AI・ChatGPTのリリースで話題爆発
2022年12月1日、アメリカの研究企業・OpenAIは「ChatGPT」のデモ版を無料で公開しました。
ChatGPTを使うと何ができるの?
ChatGPTの枕詞として付いている説明は、「会話型AI」「チャットボット」などメディア各社によってまちまちになっています。ですが、それはどういうものなのかといえば、「質問を打ち込むと回答のテキストを自動で生成する」というAI。呼び方が違っても中身は変わりません。
「質問を打ち込む」といいましたが、その質問(「プロンプト」と呼ばれる)はなにも固定された答えが存在するもの――例えば「東京でオリンピックが開催されたのは何年ですか」など――に限りません。「幸せになるにはどうすればいいですか」といった抽象的な質問でも回答の文は生成されますし、回答としてスピーチ原稿を一瞬で作らせる、新しい小説のあらすじを抽出させる、ソフトウェアのプログラム言語を書かせる、といったことも可能です。
提言:擬人化した言葉の表現に要注意
ChatGPTは、「質問すると答えてくれる」形をとり、まるで人を相手にしているかのように「会話」ができる仕様になっています。「会話型AI」と呼ぶメディアがあるのはそのためでしょう。
しかし、現実には、会話のようなやりとりはただの「演出」です。本質的にはテキストをポンと作るだけのプログラムなのですが、それでは見た目的におもしろくないので、会話のようなセリフを画面に表示するようにした、というだけです。
メディアでは、「ChatGPTに聞いてみた」などと、生成AIを擬人化した言葉の表現が多用されており、それが人々の誤解のもとになっています。テレビ局は、視聴者の興味を引くよう、話をおもしろく語りたいのです。あるいは、記者やアナウンサー自身が正しく理解できていないこともあるようです。ですが、ここまで読めばお分かりの通り、それはあくまでコンピュータープログラム。人と同じように会話ができているわけではありません。混乱しないためには、メディアから流れてくる擬人化表現をそぎ落とし、本質を分かっていることが大事です。
ChatGPTリリース後すぐさま浮上した問題点
さて、こうしてChatGPTが公開されると、「おもしろい」などと話題になった反面、すぐに問題が続々浮上。各所から反応や対応が相次ぎました。

アメリカの大学で学生が論文に利用
インターネットが出現して以来、学生がネットの情報をコピペしただけのレポートを提出した、というのは世界中の大学で問題になってきました。いつの時代も変わらない学生の性、今度は文章の自動生成です。テキスト生成AIでレポートや論文を書いてしまおうというのです。
これを受け、ニューヨークシティは教育機関でChatGTPへのアクセスをブロック。利用を禁止する措置を講じました。
内容がまちがいだらけ
ChatGPTがリリースされると、その性能はいかなるものか、世界中の様々なメディアが検証にかかりました。その結果、「出てきた文章の内容がまちがっている」というケースが次々と報告されています。
例えば、日本のITmedia Newsがアドオン「ChatGPT in Google Sheets and Docs」を使って実験したところでは、有名企業の社長の名前がデタラメだったり、トヨタ自動車の住所が東京都港区芝公園と入力されたりしています。
また、アメリカのプログラミング関係の質問投稿サイト「Stack Overflow」は、ChatGPTで生成されたプログラムを回答として投稿するのを一時的に禁止すると発表。ChatGPTが自動生成したプログラムは、間違ったものが多いにもかかわらず、一見もっともらしく見えるので、確認せずに投稿する人が多数おり、「ユーザーにとって実質的に有害だ」と判断したからでした。
このように、テキスト生成AIによって自動生成されたテキスト(文章)は、見た目がもっともらしいだけで、内容が正確でないケースが非常に多く見られます。
判定ツールもまちがいだらけ
以上のような反応や批判を受けて、OpenAIは翌2023年1月31日、テキストがAIが生成したものか人間が書いたものかを判定する無料ツールを公開しました。
ところが、その判定ツールも性能はまだまだで、誤った判定が多いことが指摘されています。実際には人間が書いた文章なのに、「AIが書いた可能性が高い」と判定してしまったりするのです。特に、英語以外の言語では精度が大幅に下がるとのこと。開発者のOpenAI自身、判定ツールは補助的に使うよう勧めていました。
判定ツールをついに取り下げ【最新】
こうして物議が続く中、同7月22日、OpenAI社は判定ツールを利用停止にしたと発表します。理由は、判定精度の低さでした。
私見
実は、テキストの自動生成プログラムというのはネット上ではかなり前から利用されていました。プログラムを使って芸能人の名前を詰め込んだ文を自動生成し(文の意味は通っていない)、自分のサイトにアップして、ウェブ検索からアクセスを集めよう、といった後ろ暗い業者がいたのです。だから私は、いくら機械学習で開発されたといえども、自動生成された文章がデタラメなのには驚きません。「開発が進んだといってもまだこんな段階なんだな」というのが正直な感想でした。
私が個人的にそれよりも気になっているのは、言語間の格差です。私はこうして自分のサイトを運営していて、Google等の自動化プログラムは、日本語だとクオリティが格段劣っていると実感しているからです。
出てきたとたん話題沸騰となったテキスト生成AIですが、開発はこれから、というのが実情でしょう。開発者がその段階で世の中に出してきたのだ、という視点も大事です。
ChatGPTとGoogleのBardを比較
そんなChatGPTに対抗策を打ち出したのが、誰もが知るウェブ検索最大手、Googleでした。同2月6日、ピチャイCEOは「実験的な会話型AIサービス」だとする「Bard」を発表。できること自体は、ChatGPTと同種です。
背景として、近年、Google社はメインである検索事業が減速していました。そこにもってきて、「質問を打ち込めば回答を出してくれる」ChatGPTの出現は、世界中の人が調べものに使っているGoogle検索にとって大きな打撃になるのでは、と投資家から懸念が出ていたのです。
ポイントとして、まず、Bardには同社の対話アプリ用言語モデル「LaMDA」が採用されています。「何のこと?」と首をかしげた読者も多いでしょうが、LaMDAといえば以前、Googleのエンジニアが「人工知能が心を持った」と大騒ぎしたことで有名になりました。このエンジニアは自分の宗教的世界観からそのようなとらえ方をしたということで、愚かな騒動として一蹴されました。
また、ChatGPTと比較すると、Bardは検索大手Googleの強みを生かし、ネット上の情報を利用するところに特徴があります。ChatGPTが「学習」しているのは2021年末までの情報ですが、ピチャイCEOが示した質問例からは、Bardはより新しい情報まで「学習」しているとみられています。
また、ピチャイCEOは、「正解が1つではない質問」に答えるための新しいAI機能をGoogle検索でも展開していくと発表。例として、「ピアノとギターのどちらが習得しやすい?」という質問でGoogle検索をかけると、トップにはAIに自動生成された回答が表示され、その下に従来の検索結果が出てくるとしています。
Microsoft VS Google―火花が散る米巨大IT間の開発競争
このようにGoogleがウェブ検索への組み込みを打ち出したのですが、実は、ChatGPTも検索と無関係ではありません。開発したOpenAIは、Microsoftから出資を受けているのです。
Microsoftは、ChatGPTを自社の検索サービス「Bing」に組み込むと発表。「ChatGPTよりもすごくなる」と自信を見せました。このタイミングで、GoogleはAIスタートアップ企業・Anthropicとの提携を発表します。アメリカの巨大IT・GAFAMの二社、Microsoft対Googleで火花が散っているのです。
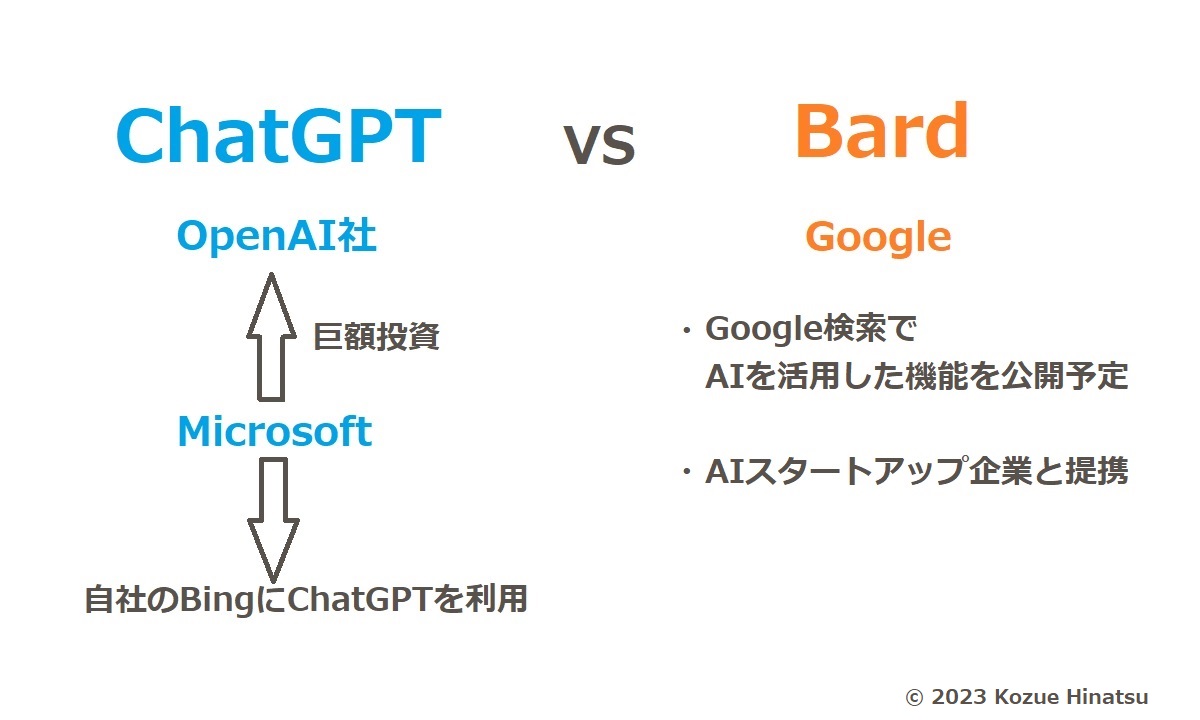
以上より、テキスト生成AIは、当面は、「テキスト(文章)を書く」というより、ウェブ検索の在り方を大きく変えるテクノロジーとして注目される見通しになっています。
さらにこの数か月後、MicrosoftのナデラCEOは、年次開発者会議「Microsoft Build 2023」で、Windowsに新AIアシスタント「Copilot(コパイロット)」を搭載すると発表しました。それによれば、Copilotは、ChatGPTと同じように質問ができ、他にもパソコンの設定変更、各アプリの起動や操作、文書ファイルを読み込ませて要約を作らせるなどができるAIアシスタントだということです。またこの発表では、ChatGPTの検索エンジンではBingが使用可能になり、同時にMicorosoft 365のCopilotはEdgeに統合されてサイドバーに常駐するなど、WindowsとChatGPTを一体化していく同社の構想が打ち出されています。
このような経緯でテキスト生成AIが組み込まる見通しとなったWindowsは、パソコンOSの世界シェアで7割以上を占める巨大な存在であるだけに、Microsoft社の動向は今後パソコンの在り方を左右していく可能性があります。
Meta(旧Facebook)はMicrosoft寄り【最新】
そんな中、同じく米巨大IT・GAFAの一角、Metaも7月18日、自社製のテキスト生成AI「Llama 2」を発表します。同社によれば、性能は、ChatGPT(3月1日版)と同等だということです。
ChatGPTはチャットボットであり、サイト上やスマホアプリとしてもリリースされたので、一般人にも遊び感覚で利用されました。一方、Metaの「Llama 2」は大規模言語モデルであり、開発者向けです。つまり、誰でもそのままで試せるのではありません。開発者がそれを組み込んだ新しいサービス等を作る、という形でお目見えすることになるでしょう。
使用は基本無料で、商用利用も可となっています。
「Llama 2」は、直接ダウンロードする以外に、Microsoftが提供する開発者向けクラウドサービス・Azureでも利用できるとしています。MetaはMicrosoftを優先パートナーと位置付けており、激化する巨大IT同士の競争ではMicrosoft寄りの立場をとっていくとみられます。
いま浮上している問題点
以上はChatGPTリリース直後に実際起こった出来事でしたが、生成AIをめぐっては他にも様々な問題が予想されています。
悪用への懸念―誰でもできるデマ作成
新しいテクノロジーが出てきた時に付き物なのが、悪用への対処です。中でも特に懸念されている生成AIの悪用法は、デマ画像やフェイクニュースでしょう。
この悪用法は、画像生成AIが話題になったそばから国内でも現れました。静岡県の水害だとするフェイク画像がSNSで拡散し、メディアが注意を呼び掛けるなど問題になったのです。このフェイク画像は、画像生成AI「Stable Diffusion」で作成されたものでした。

今のところ、画像生成AIが出力した画像は人の目で見抜くことができます。上記の水害のフェイク画像でも、本物のように見えるのはパッと一瞥したときだけ。よく目を凝らしてみてください。ビルがビルの形をしていなかったり、水の流れがある場所とない場所があったりと、不自然な箇所が多々見つかります。しかし、今後もっと正確な画像が生成できるようになるのは時間の問題とみられます。
もっとも、画像の作成・編集技術は着実に進んできており、生成AIが登場する以前から、画像の顔を入れ替えるなどは技術的に可能になっていました。有名なところだと、人気SF映画『スター・ウォーズ』で、ルーカス監督が世界観を整えるため『エピソード6』のDVDで俳優の首から上だけを別の俳優に入れ変えた、という話は有名ではないでしょうか。
こうした画像処理技術は年々進歩し、しだいに市販の画像編集ソフトでもできるようになっていきました。これを悪用する者はすでに出ており、フェイク画像が作成され、しかもその出来がどんどん本物らしくなっていったのは、生成AIが登場する前からコンピューターやインターネットをめぐる大きな問題となってきました。ソフトメーカー・AdobeがPhotoshopなど画像編集ソフトにアカウントでのログインを求めるようになったのは、自社ソフトがディープフェイクの作成などに悪用されたことが背景です。
もし悪用されれば大変なことになる画像処理は、以前は映画監督や、画像・CG等の知識を持ったプロだけが、機材を駆使して、手作業の末にはじめてできたことでした。それが、画像生成AIによって、誰でも、何の知識も必要もなく、ほんの一瞬でできるようになる。一見本当らしいプロの記者のような記事を、誰もが一瞬で作れてしまう。誰もが使える生成AIの登場により、画像や文章を作るハードルがかつてなく下がるため、フェイクが増加するのではないか、という点が懸念されています。
「機密情報が漏れる」とはこういう意味!
テレビのニュースで「ChatGPTが省庁で使われたら機密情報が流出する危険性がある」と報道されているのを見て、「ChatGPTからどうやって機密情報が漏れるのか分からない」という声を聞きました。なので、これはどういうことを言っているのか、その仕組みを説明しようと思います。
冒頭で、生成AIとは「人が入力したら、それに応じたテキストや画像などを自動で作るプログラム」だと言いました。ポイントとなるのは、「入力する」という箇所です。この部分を詳しく具体的に説明すると、入力した言葉はインターネットを通して運営会社(ChatGPTならOpenAI社)のコンピューターに送られ、それに応じた文や画像が送り返されてくる、という仕組みになっています。つまり、画面に打ち込んだ内容――例えば画像生成AIに入力した「教室で本を読んでいるかわいい女の子」という文字列――は、全て運営会社に送信されているのです。
これが省庁職員や政治家の秘書などに使われたらどうでしょう? もし省庁職員がChatGPTに「×××(※国家機密情報)の報告書を作ってください」と打ち込んだら、「×××」という文面はOpenAI社に送信されるのです。運営会社が世界中から送られてくるデータをどう扱っているか、それはその企業次第です。運営会社がサイバー攻撃を受けて情報が流出した、などということもないとはいえません。いずれにせよ、相手企業のコンピューターにワンクリックで送ってしまったものは、もう二度と手元に戻すことはできません。
加えて、上記で解説したAI特有の「機械学習」も関わってきます。相手企業のコンピューターに送信した文字列や生成されたものは、多くのサービスでは機械学習に利用されるようになっています。そのため、入力した文字列等は、どこか別の所で生成物の一部になる可能性があります。ここに機密情報が含まれていれば、それが全然知らない人のChatGPTにポッと出た、ということになりかねません。
「ChatGPTで機密情報が漏れる」というのは、こういうことを言っているのです。相手企業のコンピューターに送信されるという仕組みでいえば、以前、Apple社は、iPhoneのSiriから送られてくる音声(医師が患者に病状を説明しているとか、恋人同士の会話なども含まれる)を従業員に「盗み聞き」させていたと内部告発で明らかになり、問題になったことがあります。
参考リンク:Siriの「盗み聞き」事件(「GAFA独占の問題点と日本の現状」より)
著作権は誰に帰属するのか?
生成AIの登場は、イラストや音声関係、文章などクリエイティブな仕事に新たな可能性をもたらしました。クリエイターからは単調な作業の効率化やアイディア出しに活用できると期待の声が上がっているのですが、一方では、未知の課題も突きつけられる状況となっています。
まず一つ目は、著作権です。人工知能が生成した画像や文の著作権をめぐって、
- ソフトの開発者と利用者に法的な争いが起こるのではないか
- 利用者が手を加えた場合はどうなるのか
- 生じた果実(付随して後から生じた利益)の帰属先は誰になるのか
といった論点が予想されているのです。
権利関係については、今のところは、生成AIそれぞれの利用規約によって決められています。民事法上は規約通りに扱うのは十分合理的でしょうが、世界中で統一された判断枠組みが必要との声も出ています。
求められるクリエイターの環境整備
さらに、クリエイターは今後、作品が自動生成ではなく自身が作ったものだと証明することが必要になってくると言われています。
イラスト投稿サイト・pixivは2022年10月、利用者からの多数の問い合わせを受け、人間の手による作品とAIが生成したもののすみ分けができるようサイトに機能を追加しました。
同じく2022年10月には、画像編集ソフトメーカー・Adobeが、クリエイター本位の画像生成AIを自社で開発すると発表しました。そのツールには、コンテンツが自分の作品だと認証できる技術を組み込むとしています。
クリエイターが自身の作品であることを証明し、正当な利益を得られる環境づくりが求められているのです。
巨大ITのためにタダ働き―眼前に見えたディストピア
仕事に関わる問題の中で特に懸念されるのは、「大量のデータを取り込ませる」という開発方法が引き起こす事態です。
前述の通り、生成AIは、インターネット上に存在するデータを学習元とすることで開発が進んできました。画像生成なら、SNSに投稿された顔写真や、ウェブサイトにアップされたイラストなど。テキスト生成なら、新聞社が出した記事や、学術論文、その他無数のサイトや一般人のSNS投稿などありとあらゆる文章。このページも、です。いまこの瞬間にも、どこか見知らぬ企業や研究室の中で、機械学習は進行しています。
使用料を払わない、許可もとらない開発者―表現・言論のルール
ここで問題となるのが、著作物の使用許可や使用料です。
例えば、メーカーの宣伝担当者が雑誌を読んでいて、ある風景写真が目に留まり、自社商品のイメージに合うからパンフレットに載せたいと思ったらどうするでしょうか? その写真家に連絡を取り、使用していいかどうか、許可を求めますよね。もし「いいですよ」と言ってくれたら、コピーライトを表記し、十中八九は使用料を支払うことになるでしょう。
また世間では、イラストや音源を無断でYouTubeにアップしたらある日突然権利者が連絡してきて、削除を求められた、といった話もよくあります。
文章の関係だと、歴史や文学、病気などに関する書籍や、大学で使う学術書などをめくれば、巻末には参考文献がリストされています。他人が努力に努力を重ねて作った研究成果を流用し、まるで自分が考えたかのようなふりをするのは、言論では「盗用」というルール違反。著作物の権利関係は重要です。
しかし、どうでしょう。MicrosoftやGoogleは他人の著作物を利用して生成AIの開発を行い、巨額の利益を得られる一方、学習元となった作者には使用料が払われません。参考文献としてクレジットされることすらありません。
表現・言論の視点から見れば、他人の著作物を無断使用する企業は、表現・言論の原則に違反しているといえます。これら生成AI開発企業は表現・言論という分野に踏み込んでいるのだということを指摘するのが第一歩であり、さらに、そうである以上は、表現・言論界のルールを守らせなけらばならないと、私は本稿にて提言します。
IT企業・業界の反応は?
著作物の機械学習への利用に関し、いまのところ、米IT業界団体・ITIFは、米著作権法の定めるフェアユースにあたるとクリエイターに反論しています。
また国内では、2018年(平成三〇)の著作権法改正で、著作物をAIに読み込ませることができるとされました(30条の4)。改正の目的は、産業競争力の強化でした。ただ、同条文には
当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
とただし書きが付けられているので、もし日本で訴訟が提起された場合は、機械学習への利用が「著作権者の利益を不当に害することとなる場合」にあたるかどうかが法的な争点となるとみられます。
AIには巨額の利益がからむので、開発者には、競争で勝つため、ルールが定まらないいまのうちに開発を進めてしまいたいという本音が透けて見えます。
他方、開発への反発は、著作物を持つクリエイターだけでなくIT業界内部からも出ています。2023年3月には、TwitterのCEOとして知られるイーロン・マスク氏を含む1000人以上のIT関係者が、少なくとも半年間人工知能の開発を停止するよう求める公開書簡を公開しました。
それは盗用、盗作ではないのか
手塩にかけて制作したイラストや文章が、好むと好まざるとに関わらず機械学習に利用される。これだけでも十分問題ですが、事はそれだけで終わりません。
まず、生成AIがクリエイターが作った著作物から学習し、クリエイター本人とよく似たものを生成したら、それは盗作ではないのかという問題点があります。盗作の問題については、すでに海外でOpenAIやGitHub(Microsoft傘下のソフトウェア開発サイト)など開発者を相手取った訴訟が次々と提起されています。
そのあげく、生成AIの開発が進み、将来ChatGPTやBardが生成した回答で人々が事足りるようになれば、学習元になった原著作者のほうがお払い箱になってしまいかねません。世界中で行われる仕事が、巨大ITのためのタダ働きになる――そんな暴力的な産業構造が出来上がる危機が、一気に目の前までせまったのです。
この問題点は、画像を生成する「Novel AI」が無断転載サイト「Danbooru」を学習元としていたことで物議になり、以後、広く議論されるようになっていきました。クリエイターの間では、自分の作品が無断で学習元にされていることに抗議したり、機械学習への利用を拒否できるシステムを模索したりといった動きが現れています。機械学習という特殊な方法を用いる人工知能の開発では、利用したデータの透明化が求められています。
インターネットで起こりつつあったGoogleへの追従
以上、ここまでは基礎の基礎からわかりやすく説明してきましたが、ここから先はうんと踏み込んだ話になります。
私は今回、実は、クリエイターが巨大IT企業に利用されるようなことはウェブ検索においてすでに起こりつつあったのだ、ということを指摘したいと思います。
かくしてインターネットは自由な創造を失っていった
人々がインターネットで検索を行うようになり、検索が社会で強い影響力を持った結果、社会には「Googleの検索結果で上のほうに表示されたい」という需要が生まれました。上にいけばいくほどサイトへの訪問が増えるからです。
デジタル時代、ビジネスにとってインターネットの活用は必須です。自社紹介を目的とするサイトならまだしも、オンラインショップやメディア系のサイトなら、検索での順位は売り上げに直結します。企業はライバル社に勝つため、Googleが示したサイトのガイドラインに沿ったコンテンツを作るようになっていきました。
表現の自由への新たな脅威
サイトをGoogleの望みにすり合わせざるを得ないというだけでも自由な表現・言論にとって非常に有害ですが、実は問題点はそれだけにとどまりません。
Googleは、自動化プログラム(クローラーと呼ばれる。これも人工知能)を用いて世界中のありとあらゆるウェブページの内容を評価をして回っています。自社の検索結果を作成するため、また、詐欺サイトやマルウェア、盗用といった悪質なページを検索結果から除外するためです。
IT企業が他人のサイトの内容を評価する、という立場関係には違和感を感じたかもしれません。「自由な表現」という観点からは、思わず身構えた読者もいるでしょう。ですが、これにはれっきとしたいきさつがあります。Googleにも言い分があるのです。
ウェブ検索がインターネット上で強い影響力を持つようになったことは、悪質なページが大量に作成される事態を引き起こしました。検索結果で上位に表示されたいがために、手段を選ばない人や業者が湧いて出たのです。いくつか例を挙げると、人々の関心が高い芸能人の名前を羅列した意味の通らない文をサイトに載せる、他サイトから文章をコピペしてページを量産する、サイトのテーマと一切関係ないページを作る(中古車販売会社がブログに焼き肉のおいしい焼き方を書く、株式投資の情報サイトに金魚の種類を解説したページがある、など)といった行為が世界中で横行。結果、インターネット上には、著しく質の低い情報が氾濫し、Googleはその土壌を作っているとして批判されました。
これを受け、Googleは悪質なページを排除、または検索結果で影響力を持たないようにすることに注力します。自動化プログラムの改良を重ね、サイト運営者向けにはガイドライン(現・検索セントラル)を公開。その結果、今日では著しく質の悪いページは検索結果から姿を消しました。
ただ問題は、この自動化プログラムは完全ではなく、誤判定を下すことがあるということです。たとえ社会問題の解説記事やただの日記でも、「これは悪質なページだ」と間違って判定されたら最後、Googleの検索結果から抹消されるなど、多大な不利益を被ってしまうのです。
提言:サイト管理人として筆者自身の経験から言えること
筆者は、文章を執筆するだけでなく、このサイトのウェブマスター(管理・運営者)でもあります。そのため、インターネットの世界におけるGoogleの存在と影響力の途方もない強大さは、自分自身の表現・言論活動を進める中で、身をもって感じてきました。
実を言うと、筆者には、上記のようなGoogleの誤判定によって、多大な不利益を被った実体験があります。これまでに、分かっているだけで3回、当ブログの一部の記事がGoogleの検索結果から消えたのです。2021年には13記事、2022年には4記事、2023年には13記事。悪質だと判定された記事は、オリンピックの歴史や、誹謗中傷の解説などです。ちょっと読んでみてください。人が読めば、詐欺等とは縁もゆかりもないごく普通の文章だとすぐ分かります。もちろん技術的にも詐欺的なプログラム等は組み込んでおらず、3つのマルウェアスキャンをかけて異常は見つかりませんでした。
筆者は、サイトへの訪問者が減ったことで異変に気づきました。当サイトでは、読者の約9割が検索経由でアクセスしており、サイト訪問者全体のうちGoogleからのアクセスは約7割にのぼります。
この由々しき問題に対する私の考えはサイトの運営ポリシーで書ききったので、以下に抜粋しておきます。
これは表現者およびウェブサイト運営者である管理人にとって理不尽な活動妨害であり、また社会的にも表現の自由にとって新たな脅威であるのは明らかです。
ただ現実問題として、Google等は表現者が判定に異議を申し立てられるシステムを設けていません。具体的にどの箇所が、なぜ、どのように悪質なコンテンツと判定されたのかも表現者側には知らされず、調べる手立ても存在しません。表現者側がページ中の文や構成、画像等を手探りで修正し、どこかの時点で誤判定が解けるのを待つしかないのが現状です。
信じられない、と目を疑った読者もいることと思いますが、全て本当にあった出来事です。
筆者とGoogleの間には雇用関係はありません。それどころか、互いに面識すらありません。私は私、同社は同社で、完全別個に活動しています。にもかかわらず、Googleは一方的に表現物の良し悪しを評価する立場に就き、お粗末なレベルの「かん違い」によって、他人の表現物を「焚書」にしている。他方で筆者は異議を述べることすらできず、誤判定への対処はこちらが一方的に負担しているのです。
しかも、Googleはサイトの質をどのように判断しているかを公開していません。したがって、たとえどんなに不利益を受けても、表現者側がその証拠をつかむことは困難です。
同社のウェブマスター向けガイドラインに関しても、机上の空論にすぎない側面は確実にあると思います。筆者はサイトを管理運営する中で、同社の主張とは裏腹に、クオリティがいまひとつでも無難なページや、オリジナリティがなく他サイトと同じことを書いているページのほうが高く評価される傾向にあると感じています。自動化プログラムの精度は、まだ十分からは程遠いのではないでしょうか。
ネット上で何かを始めれば、Google社と関わらざるを得なくなる。自分のビジョンに沿ってプロジェクトを進めていたはずなのに、いつの間にか同社のためにタダで働く羽目になってしまう。インターネットは、そんなおどろおどろしい世界になりつつありました。
文章や言葉の選び方は、表現者の自由です。ウェブサイトのデザインや構造、組み込む要素はウェブマスターの自由です。にもかかわらず、インターネットがGoogleの意向に支配され、個人の自由が阻害されていることに、私はかねてより問題意識を持ってきました。いまの時代に実体的な表現の自由を守るには、検索事業を展開するIT企業に対し、国際的なルールを整備することが必要だと私はここで提言します。
巨大IT独り勝ちという未来への懸念
人工知能がブームになりつつあった頃から、世間には「AIによって人間が不要になる」とか「人類は滅ぶ」といったセンセーショナルな情報があふれてきました。テレビ局は興味本位のおおげさな特集を家々に流し、書店では立派な肩書きを引っさげた学者のまことしやかな著書が棚から次々羽ばたいていきました。そういった金儲け目当てで作られた情報をうのみにして、不安になったり、誤解したり、混乱したりする人が大勢出ました。私が以前人工知能全般について解説した時、最も強く問題意識を持ち、正したかった側面です。
そしていま、新しい種類の人工知能がもたらしたのは、SF映画から取り出したような未来ではなく、いたって現実的な状況でした。テキスト生成AIが実用レベルに達してリリースに至り、ChatGPTやBardがウェブ検索に組み込まれる公算となったことで、巨大IT企業独り勝ちという未来が一気に現実味を帯びたのです。
生成AIには巨額の利益がからむので、国家間の競争でも重要なファクターとなっています。その研究開発には、国際的なルール作りが求められています。
関連記事・リンク
著者・日夏梢プロフィール||X(旧Twitter)|Mastodon|YouTube|OFUSE
人工知能(AI)の問題点・デメリット5選と、人間の未来 – 人工知能全般の問題と、仕事への活用など新たな可能性について網羅した解説です。以前は生成AIの解説もこちらの一部だったのですが、大ボリュームになり、読者にとって該当箇所が探しにくくなっていたので、今回単独で記事にしました。全体像を理解するために併せて参照ください。
GAFA独占の問題点と日本の現状・課題 – 巨大ITの市場独占がどのような問題を引き起こしているかを解説しました。冒頭でまとめた予備知識を読んでおけば、新しい人工知能であれ何であれIT業界の話題全てに応用のきく頭になれますので、ぜひ併せてお読みください。
YouTuberの行く末~問題とその後を解説 – Googleによる動画削除など、関連事項を扱っています。
YouTubeへの動画投稿を始めました – 筆者が動画投稿を始めた告知ですが、世界中の動画制作者がYouTube(Googleの子会社)に隷属させられるかのような産業構造に触れていますので、興味があればこちらもどうぞ。
プライバシーポリシーを楽に読む方法 – 巨大IT企業が個人情報をどう扱っているかを知るには、とりあえずプライバシーポリシーを読まないことには始まりません。とはいえ、ほとんどの人が読まないで「同意」をしているのが現状。そこで、長く難しい条文を読むコツを解説してみました。
芸能人の薬物依存疑惑・逮捕と自主規制―「作品に罪はない」議論を徹底解説 – 私の表現・言論活動のビジョンと問題意識はこの記事でほぼ分かると思います。第三次産業革命であるインターネットの有効活用を訴えています。
当サイトのサイトポリシー – 筆者の誤判定への対処をポリシーに入れてあります。
【主要参考資料】
『マンガでわかる人工知能』三宅陽一郎監修、備前やすのり・マンガ(池田書店、2018年)
『人工知能は人間を超えるか ディープラーニングの先にあるもの』松尾豊(KADOKAWA、2015年)
他、本文中外部リンク
(性質上、本稿は更新されることがあります。2023年5月27日公開。最終更新:同7月31日。)